Leader Instances in AWS Auto Scaling Groups
When using autoscaling groups to build highly available applications, there’s often a need for one instance within the cluster to play the role of the leader. This is useful when there are multiple machines capable of performing a task or making a decision, but only one should actually do so at any given time. A good example of this is the execution of scheduled jobs which cannot be done in parallel.
In this post, we’ll walk through a scalable solution to this problem which can easily be applied to all of your Auto Scaling Groups using native AWS services.
The Solution
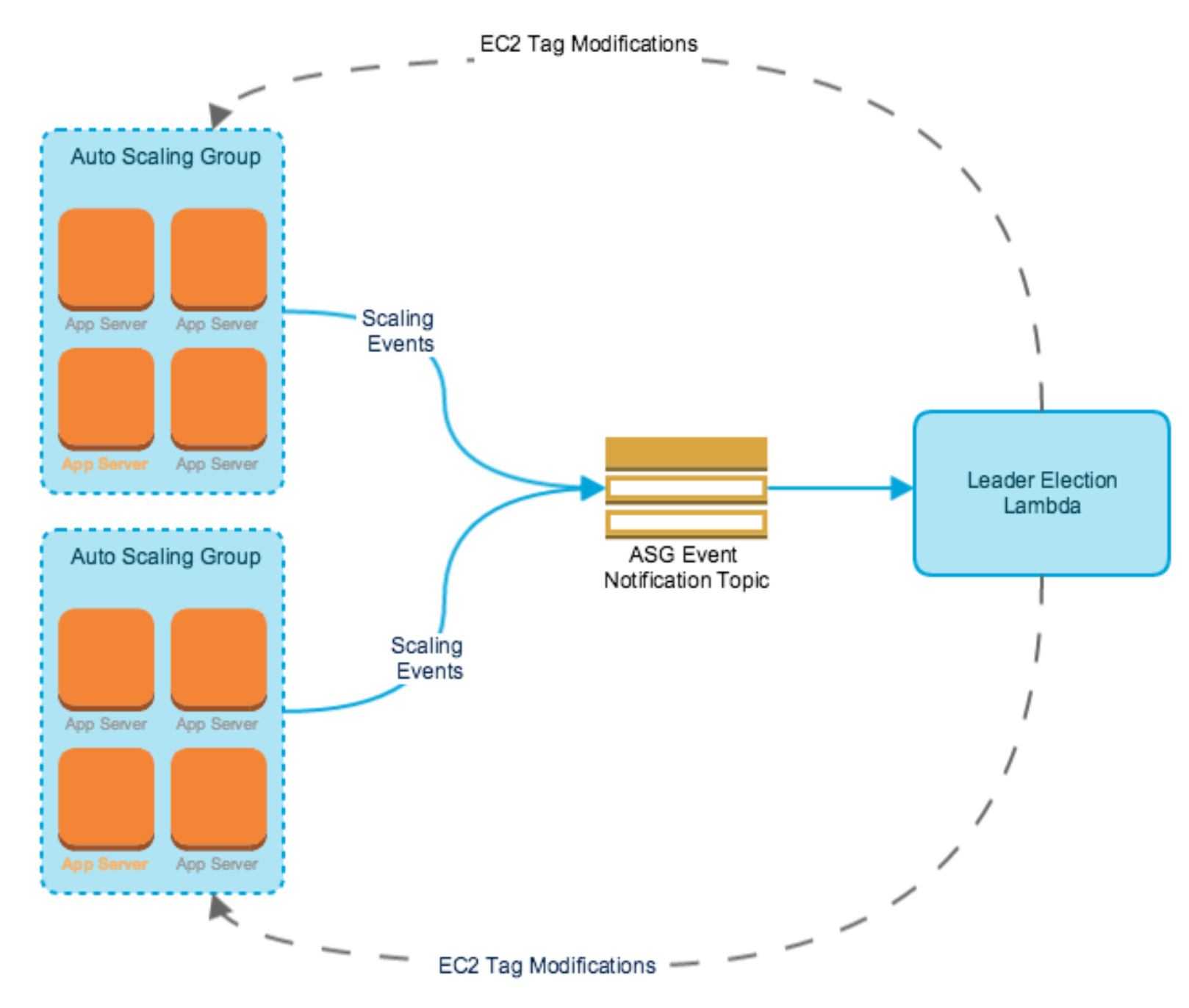
Since AWS treats all instances within an Auto Scaling Group equally we’ll need to roll our own solution. We’ll use Auto Scaling Event Notifications to trigger a Lambda function which will perform leader election for us, keeping our solution completely transparent from our application and maintaining automatic scalability.
If you’re using ElasticBeanstalk for your application, you can leverage leader_only option within your
.ebextensionconfig files to configure a single instance as the leader.
Our leader election solution will handle the following for our ASG:
- When a new instance is added, determine if it should become the leader.
- When the leader instance is terminated, select a new leader.
- When a leader is selected, make sure it is the only leader.
As with any of our solutions, it must be able to work at scale. We should assume that instances can be added and removed from the autoscaling group at any time for a variety of reasons including automatically terminated unhealthy instances.
Implementation
Want a short cut? Check out my Terraform module implementing the Lambda, SNS topic, and subscription.
1. Create an SNS Topic to receive autoscaling events.
Our AutoScaling Groups will be configured to send a message to this SNS topic whenever a scaling event occurs. When the message is received, it will trigger our leader election Lambda function (created above), passing it the scaling event.
This topic can receive messages from all of the autoscaling groups we want to participate in leader election. The message that’s sent to our Lambda function contains a reference to the autoscaling group, allowing it to only make changes to the appropriate ASG.
Note: At this time, Amazon’s documentation does not explicitly state delivery guarantees from SNS to Lambda. However, Amazon does guarantee delivery to SQS queues, which leads me to believe Lambda delivery is also guaranteed. Do not just take my word for it in mission-critical scenarios, though!
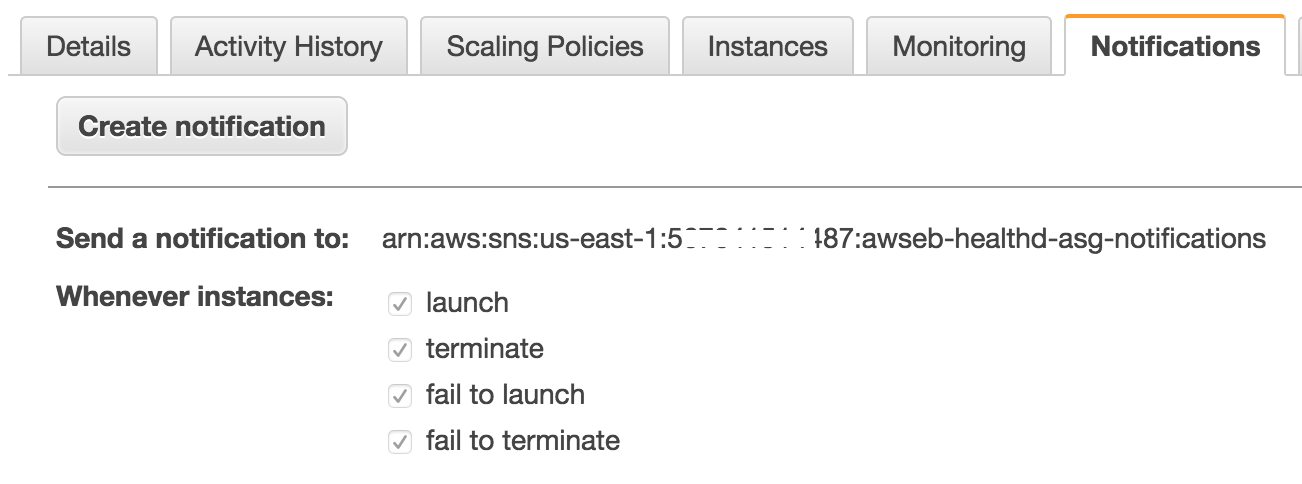
2. Enable AutoScaling Notifications
AutoScaling Groups can be configured to send notifications to one ore more SNS topics whenever an instance is launched, terminated, failed to launch, or failed to terminate. Any of these actions can mean we need to elect a new leader, so we need to enable these notifications and have them sent to the SNS topic we configured above.
3. Create the leader election Lambda
The actual work of selecting an instance to become the leader is performed by a Lambda. The Lambda will receive a notification from an autoscaling group informing it of a scaling event, and it will use that to determine if a new leader must be chosen.
The leader will be selected by examining the tags of all instances which are not terminating. If there is already a leader, it will be kept, otherwise a new leader is elected from the eligible instances.
4. Create a Subscription for the Leader Election Lambda
In order for our leader election Lambda to receive scaling events through the SNS topic, we must create a subscription on the SNS topic we created. Make sure you apply the appropriate role permissions to invoke the Lambda, or you may find that executions never happen.
Using Leadership
An instance of the application can determine if it’s running on the leader instance by using instance metadata and the AWS SDK (or the instance metadata http endpoint from the command line). If the instance has the “app:isLeader” tag, it is the current leader.
PHP Example
Conclusion
By taking advantage of autoscaling events and instance tagging, we can build a
very scalable solution for electing a single instance within an ASG as the leader.
Because tags are available through instance metadata, applications running on
instances in these auto scaling groups can easily determine if they are the current
leader.
I’m currently using this solution as a core feature of my infrastructure in many environments, and it works extremely well. I’m always looking for feedback on how to improve these solutions, so please reach out if you choose to use this in your environments as well.